
DeepSeek V3与CUDA解耦:国产AI算力芯片的崛起?
华泰证券近期发布研报指出,DeepSeek在V3版本中采用PTX指令集优化硬件算法,此举意图绕开CUDA,加速模型训练。PTX作为CUDA编译的中间代码,位于CUDA和最终机器码之间,此举使得DeepSeek能够更直接地与底层硬件交互,提升效率。
相比之下,另一些AI加速方案,例如基于OpenAI Triton的方案,则允许开发者使用更高级的编程语言编写GPU代码,同时支持CUDA、ROCm以及国产算力芯片的指令集,例如寒武纪思元590和海光信息深算一号(DCU)的HYGON ISA。这意味着Triton能更好地适应多样的硬件平台。
虽然目前大型语言模型(LLM)的训练仍依赖CUDA生态,但DeepSeek和类似的尝试正在逐步打破这种依赖。DeepSeek V3使用PTX的策略,以及Triton语言对多种GPU的支持,都展现了AI加速领域与CUDA解耦的趋势。这种解耦不仅能提高效率,还能增强AI系统的灵活性,使其能够更好地适应不同厂商的硬件。
值得关注的是,以异腾为代表的国产AI加速芯片已经能高效适配DeepSeek-R1等国产模型。在国际形势日益复杂的大环境下,海外算力受限的风险日益增加,针对国产算力芯片的优化势必成为未来发展的重点。华泰证券的报告也强调了这一点,认为未来国产算力芯片适配和优化的进展值得密切关注。
总而言之,DeepSeek V3采用PTX指令集的举动并非孤立事件,而是国产AI算力芯片蓬勃发展的一个缩影。未来,随着更多类似技术的涌现,AI领域可能会出现一个更加多元化和开放的硬件生态系统,从而摆脱对单一厂商的依赖,进一步推动人工智能技术的发展与创新。
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。

Cookie.fun爆紅:AI數據平台InfoFi掘金,解鎖數據定價權與資訊平權,社群積分SNAPS攻略。

特朗普晚宴解密:BitMart創辦人揭秘加密貨幣社群與政策制定者的潛在交流,比特幣再探10萬美元

川普晚宴揭秘:Web3權力交匯,比特幣狂舞與監管迷霧下的投資轉機

比特幣四月王者歸來,蔡依林式逆襲!摩根大通解析美股、ETF資金流入,孫興慜難比其驚喜。
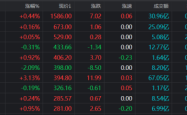
北證A股狂潮:錦波生物股價逼近550元,王文洋包養舊聞再引關注
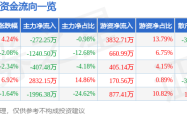
萬潤新能520後股價解析:游資湧入,散戶退場,營收增長難掩利潤下滑,如同蘇花公路開快車
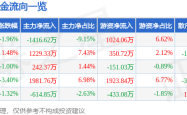
開普雲股價520資金暗湧:主力遊資博弈,數智轉型挑戰與機遇

股市「蘇花公路」路怒症發作?納指陽線藏隱憂,A股十字星示警,資金退潮訊號浮現
